







By: Arif Khan.
Now a days web scraping is very popular to extract data from web sites. In this blog we will be using node js for web scraping using very popular packages (axios and cheerio ). Let’s jump into topic.
Prerequisites.
What we are going to scrap?
We are going to scrap the site which is https://www.manchestereveningnews.co.uk/sport/football/ from this site we will scrap headlines and the link of articles. So, let’s start building the environment. Open the vscode if you don’t have vscode installed in your system then click on Node js link above.
Building Environment
First you need to create a project directory in your system, go to DOS prompt by writing command in search window, and right click on the Command prompt select Run as Administrator from context menu. Then cd into your working project directory and write (code .) and press enter. Vscode will be opened under your working directory.
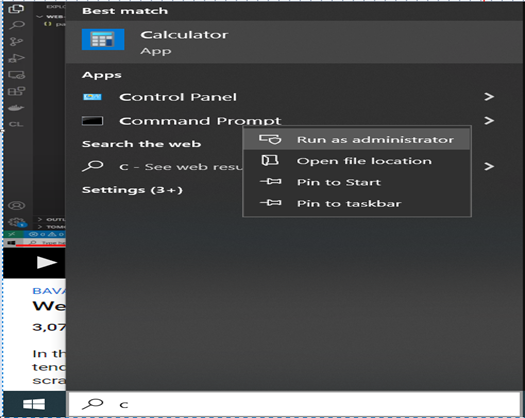
Now as you are in the vscode use shortcut key CTRL+SHIFT+` last one is back tick you can find it right under the Esc Key of your Keyboard, this short cut command will open the new terminal for you in vscode or you can open new terminal by selecting the Terminal menu. Now we need to create node js application, for this we need to write command in terminal. This command will create a new node js application and will create package.json file you can click it to see its contents.
Application initialization
npm init –y{
“name”: “your-application-name”,
“version”: “1.0.0”,
“description”: “”,
“main”: “index.js”,
“scripts”: {
“test”: “echo \”Error: no test specified\” && exit 1″
},
“keywords”: [],
“author”: “”,
“license”: “ISC”,
}
Now we have the node js application and also got package.json this json file is just like the manifest you can also change the values of each key as per your requirement. Whenever we install any dependency package this file will be updated automatically with the name and version of that package. Let’s install some dependency packages for our scraping application, for which you have write below commands in your terminal.
npm install express
npm install axios
npm install cheerio
npm install nodemon –save-dev
After execution of above commands your json will be updated as below.
“name”: ” your-application-name”,
“version”: “1.0.0”,
“description”: “”,
“main”: “index.js”,
“scripts”: {
“test”: “echo \”Error: no test specified\” && exit 1″
},
“keywords”: [],
“author”: “”,
“license”: “ISC”,
“dependencies”: {
“axios”: “^0.27.2”,
“cheerio”: “^1.0.0-rc.12”,
“express”: “^4.18.1”,
},
“devDependencies”: {
“nodemon”: “^2.0.13”
}
}
Axios will be used to fetch the data from web url actually axios is a promise based HTTP client for node js by which we can send requests to the server and receive a response in short it will return us the HTML code of the web page.
Cheerio is a Javascript technology used for server-side web-scraping implementations. It will extract the data from HTML code of the web page which we take with the help of axios.
Here we will use Nodemon to control our node server for development purpose. After have nodemon installed you just have to remove the “test” key from package.json file with following key value paires.
“start”: “node index.js”,
“dev”: “nodemon index.js”
One more thing to add in this json file is under the main key add one more key which is (“type”: “module”,). With the help of module we will be able to use import rather than require.
Ready to start coding
Now we are ready to start our development work.
Go to vscode navigator add a file and name is as index.js press enter.
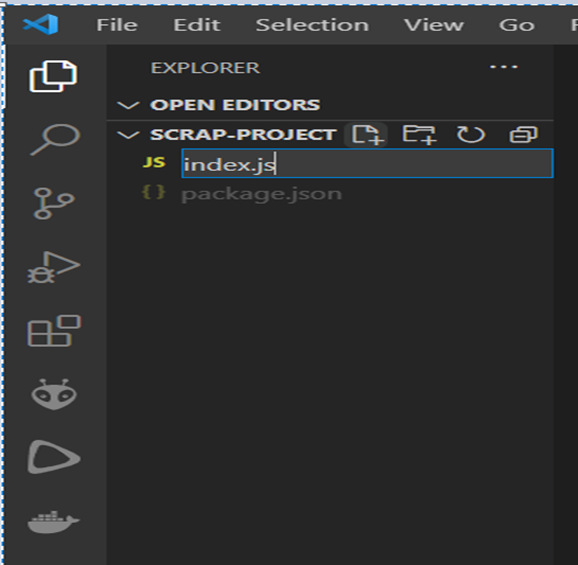
First of all import the required modules.
import axios from ‘axios’
import cheerio from ‘cheerio’
import express from ‘express’
After that we mention a PORT if we configure the environment variable then it will pick the port from there otherwise 5000 will be our PORT to execute express server, after that we will declare our server app as express().
const PORT = process.env.PORT || 5000
const app = express()
As we are going to scrap the a site as mentioned earlier, we pass the url inside axios to get the HTML code of that site, once HTML code fetched, note that axios is work like async await once it finish data fetching then we will have the response then the next instruction will be executed, that is why we will put .then. We also declare three variables inside the function to store the response HML code data, elements of HTML code and an array to store extracted titles text and it’s url like below code snippet.
const URL = 'https://www.manchestereveningnews.co.uk/sport/football/'
axios(URL)
.then(res => {
const htmlData = res.data
const $ = cheerio.load(htmlData)
const articles = []
As you see above we use $ as a variable to store the all extracted element of HTML code. Now we are able to get the any element by any querySelector you can google about java script querySelectors. Here we will use the classes like .teaser and .headline. You will find these classes by inspecting the site’s web page. First of all we will extract the .teaser class from htmlData and loop over it’s elements using each then from each element we will extract .headline class text for titles and its titleURL, in the las we will push the extracted data to an array for future use. Let us write rest of the code to extract the data from those classes.
$('.teaser', htmlData).each((index, element) => {
const title = $(element).children('.headline').text()
const titleURL = $(element).children('.headline').attr('href')
articles.push({
title,
titleURL
})
})
console.log(articles)
We will now close the code with .catch to get any error if arise.
}).catch(err => console.error(err))In the last we need to listen our express server by using below line of code.
app.listen(PORT, () => console.log(`Server is running on port ${PORT}`))All lines of code will be look like below. You can try it by yourself.
import axios from "axios"
import cheerio from "cheerio"
import express from "express"
const PORT = process.env.PORT || 5000
const app = express()
const URL = 'https://www.manchestereveningnews.co.uk/sport/football/'
axios(URL)
.then(res => {
const htmlData = res.data
const $ = cheerio.load(htmlData)
const articles = []
$('.teaser', htmlData).each((index, element) => {
const title = $(element).children('.headline').text()
const titleURL = $(element).children('.headline').attr('href')
articles.push({
title,
titleURL
})
})
console.log(articles)
}).catch(err => console.error(err))
app.listen(PORT, () => console.log(`Server is running on port ${PORT}`))
That’s all, it is a short introductory code for understanding for whom who wants to step into the field of web scraping.
Your are always welcome to write comments and suggestions.

