By: Bhagesh Kumar.
Hi Everybody. As we Know Portable Document Format (PDF) is most widely used document format in current time. It is used in each industry or business sector such as offices, universities, businesses and also for personal work. The type of data available in pdf is big and unstructured which is quite complex to understand so we need clear concise and meaningful data from this big document by extracting or scrapping the data.
Available Resources:
There are plenty of Python libraries and paid-tools available for extracting the data from PDF such as pyPDF2, PDFMiner, Tabula-py and Camelot etc. Here I am using Camelot and which is Python library and command-line tool used to read and extract data from PDF to tabular format.
My solution:
In this tutorial I will tell you, how to extract the data from PDF using Python, Camelot and Ghostscript.
First you need to install ghost script from given link Ghostscript.
For windows add Ghostscript path in environment variable.
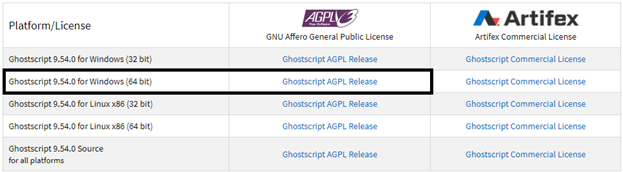
See if Ghostscript installed correctly in windows environment:
You can run the following checks to see if the dependencies were installed correctly.
from ctypes.util import find_library
find_library("".join(("gsdll", str(ctypes.sizeof(ctypes.c_voidp) * 8), ".dll"))the output of above code should not blank. if it is blank then, check it is in system path or not.
How to install Camelot:
With PIP the installation is quite easy, don’t forget to use virtualenv, so that, other modules might not effect due to any version conflict.
pip install CamelotHope you install the library successfully. Now let’s go deeper to work with this library.
First you have to import this library using python import command. Here I am using Jupyter Notebook you can use different IDE such as PyCharm, Spyder etc.

PDF source:
You can download the pdf sample from the given link, or you can use your own PDF. https://camelot-py.readthedocs.io/en/master/_static/pdf/foo.pdf
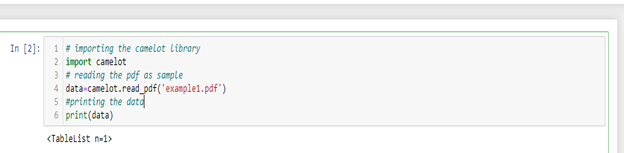

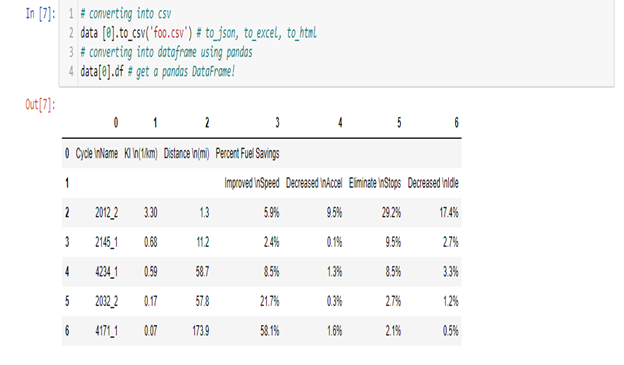
Hope this document will help you in your work.
Looking forward to hear from you in comment section.